第三章 完全且完美信息动态博弈
1. 基本知识
1.1 表示法:
- 扩展形:由于动态博弈含有多个决策阶段,又称为“多阶段博弈”。用一颗树来表示动态博弈的过程被认为是理想的,这能体现选择次序和博弈阶段。
- 得益矩阵形:又称策略形,即把各个博弈方完整的决策链条的“总计划”像静态博弈那样写成得益矩阵。本质上,就是把扩展形这棵树写成矩阵形式。
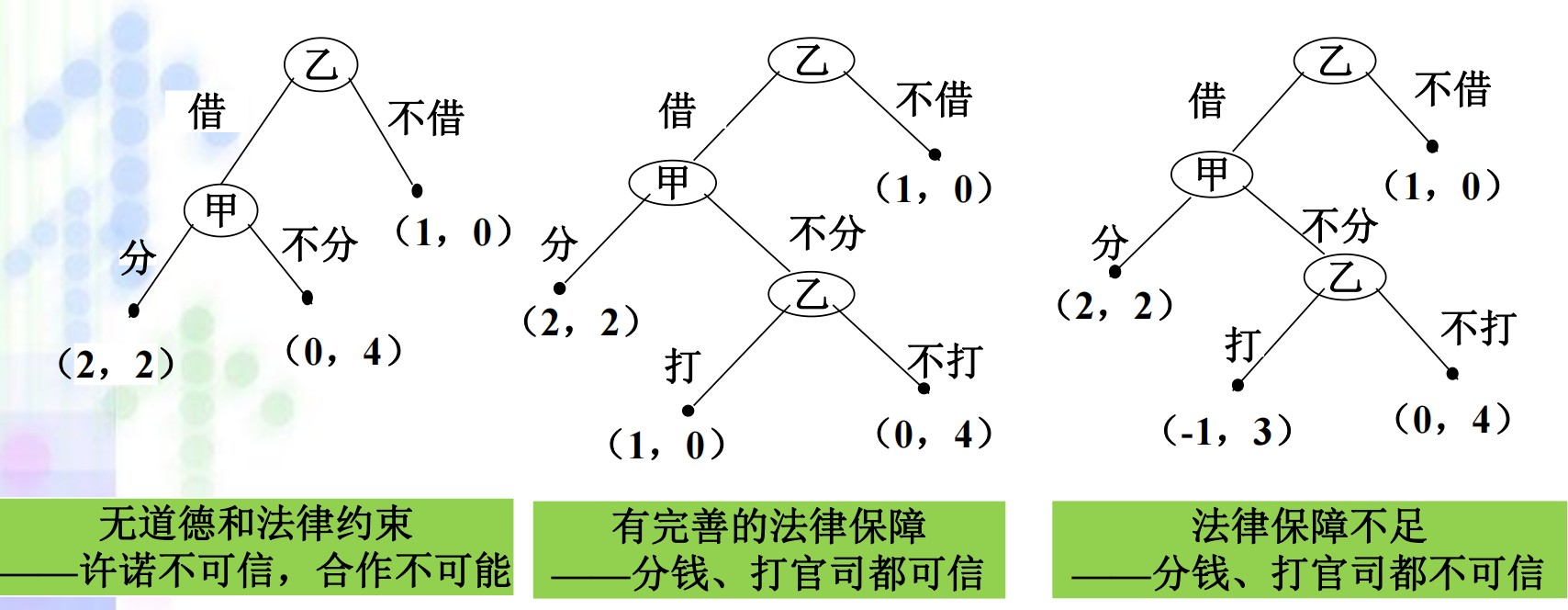
1.2 基本特点: 一个完整决策计划对应一个结果;动态博弈具有不对称性。不对称性会引发“相机选择”问题,即“可信性”的问题。
1.3 分析方法:
- 逆推归纳法:从动态博弈最后一个阶段博弈方的行为开始分析,逐步倒推回前一个阶段相应博弈方的行为分析,一直倒推至第一个阶段的博弈方的行为分析,最后对倒推分析进行归纳总结的博弈分析方法。
- 顺推归纳法:根据博弃方在博弈前面各阶段的行为(包括偏离特定均衡路径的行为),推断他们的思路并为后面阶段博弈提供依据的分析方法。
2. 子博弈完美纳什均衡
2.1 子博弈: 定义:由一个动态博弈第一阶段以外的某阶段开始的后续博弈阶段构成,有初始信息集和进行博弈所需的全部信息,能够自成一个博弈的原博弈组成部分。
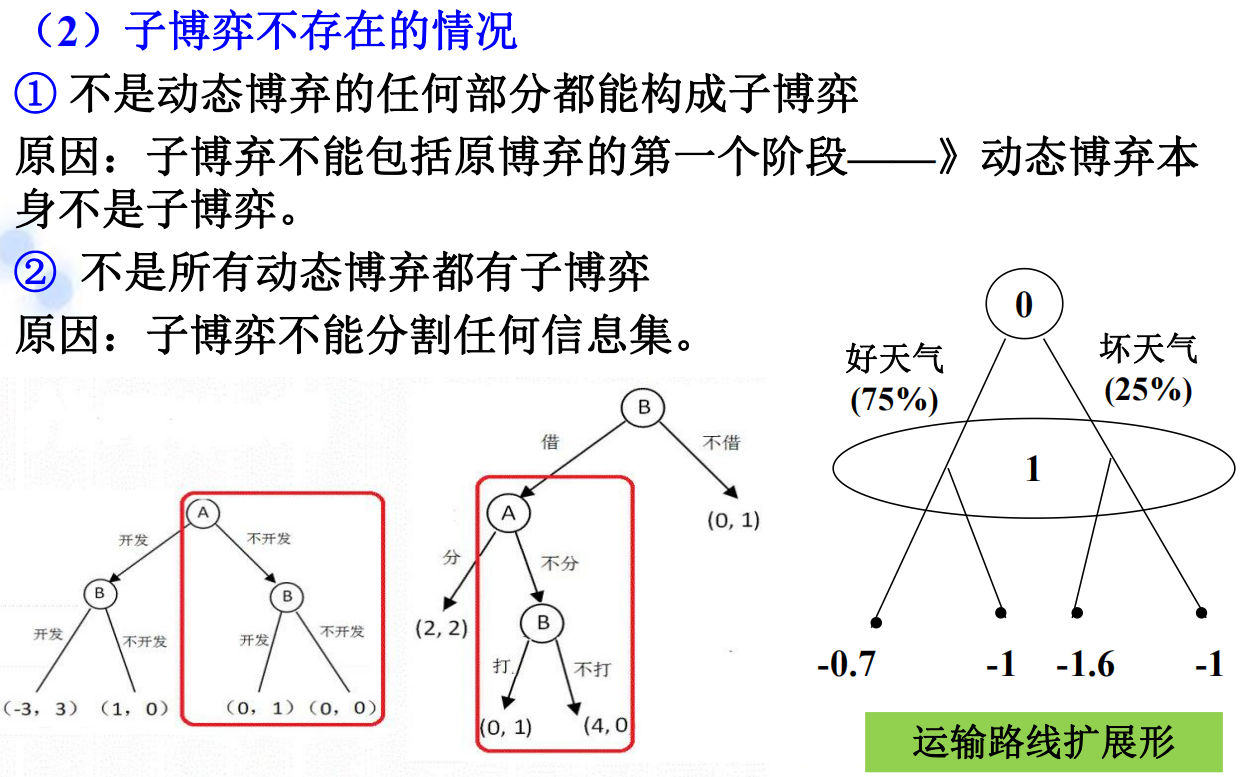
2.2 子博弈完美纳什均衡: 由经济学家泽尔腾提出。 定义:如果一个完全且完美信息动态博弈的一个策略组合,满足在整个动态博弈及它的所有子博弈中都构成纳什均衡,那么该均衡就是一个子博弈完美纳什均衡。 在子博弈完美纳什均衡中,在扩展形上有一个实际决策组合产生的均衡路径,而有些结点不在路径上,但那些结点上的选择也对整个均衡的有着重要作用,不能说就不看了。
*2.3 经典博弈例子:
2.3.1 抢20博弈: 用逆推归纳法,我抢20\(\Rightarrow\)你得到18或19\(\Rightarrow\)我抢17...最后类推得到抢\(2\equiv 20\,\text{mod}\,3\) 。
2.3.2 寡占的斯塔克伯格模型: 列出得益函数,采用逆推归纳法可知,得益函数跟古诺博弈是一样的,但由于决策先后,后决策的最优产量被先决策的博弈方的产量完全确定,这种不对称性造成了差异。
2.3.3 分配方案博弈: 体现双方的不对称性。用逆推归纳法可求解。注意仔细分类归纳讨论。
2.3.4 委托--代理博弈: 又可以分为无确定性的,有不确定性可监督的,有不确定性且不可监督的,连续条件的。都使用逆推归纳法,画出扩展形。连续报酬和连续努力水平的情况下画不出扩展形,但也只需初等的数学计算。
3. 有同时选择的动态博弈模型
3.1 标准模型: 四个博弈方,第一阶段其中两个同时进行决策,第二阶段两外两个在观察后同时进行决策,得益得以最终确定。
3.2 求解与例子: 依然用逆推归纳法,但博弈的一个阶段可以用得益矩阵来表示。最初阶段的得益矩阵可能依赖于后续阶段,通过逆推归纳法可以使其确定。记得分析子博弈完美纳什均衡,这样的决策组合才是具备稳定性的。
*3.3 存款与挤兑博弈: 逆推归纳法,从第二个阶段得益矩阵中出发,讨论两种子博弈的纯策略均衡的情况(到期,到期)和(提前,提前),将得益写道第一个阶段博弈的(存款,存款)中,再对得益矩阵分析。最终获得两个子博弈完美纳什均衡。结论也很朴素:存就共同等资金回流,怕挤兑就不要存。
4. 反思逆推归纳法
4.1 逆推归纳法的问题:
- 如果可能路径(尤其是博弈结束的可能情况太多)太多,有推理困难。
- 对理性要求较高,依赖所谓理性的共同知识,其实解决问题可能还需要考虑其他博弈方偏离子博弈纳什均衡的情况。
4.2 蜈蚣博弈: 蜈蚣博弈解释了逆推归纳法的局限性。在阶段较少的蜈蚣博弈中合作的可能更低,逆推归纳法比较符合;但在阶段多的情况下理性的博弈方更倾向合作先把蛋糕做大,再在一个普遍更高的得益水平上进行竞争。
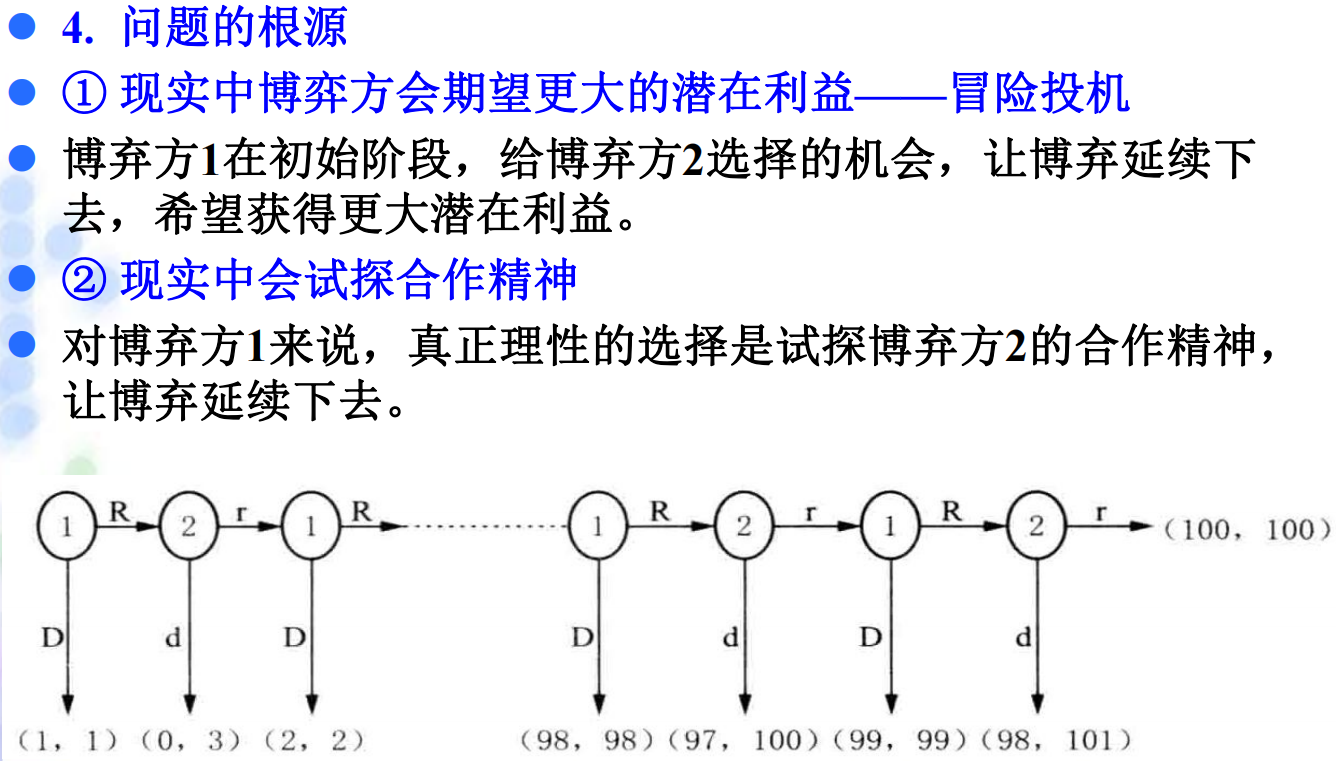
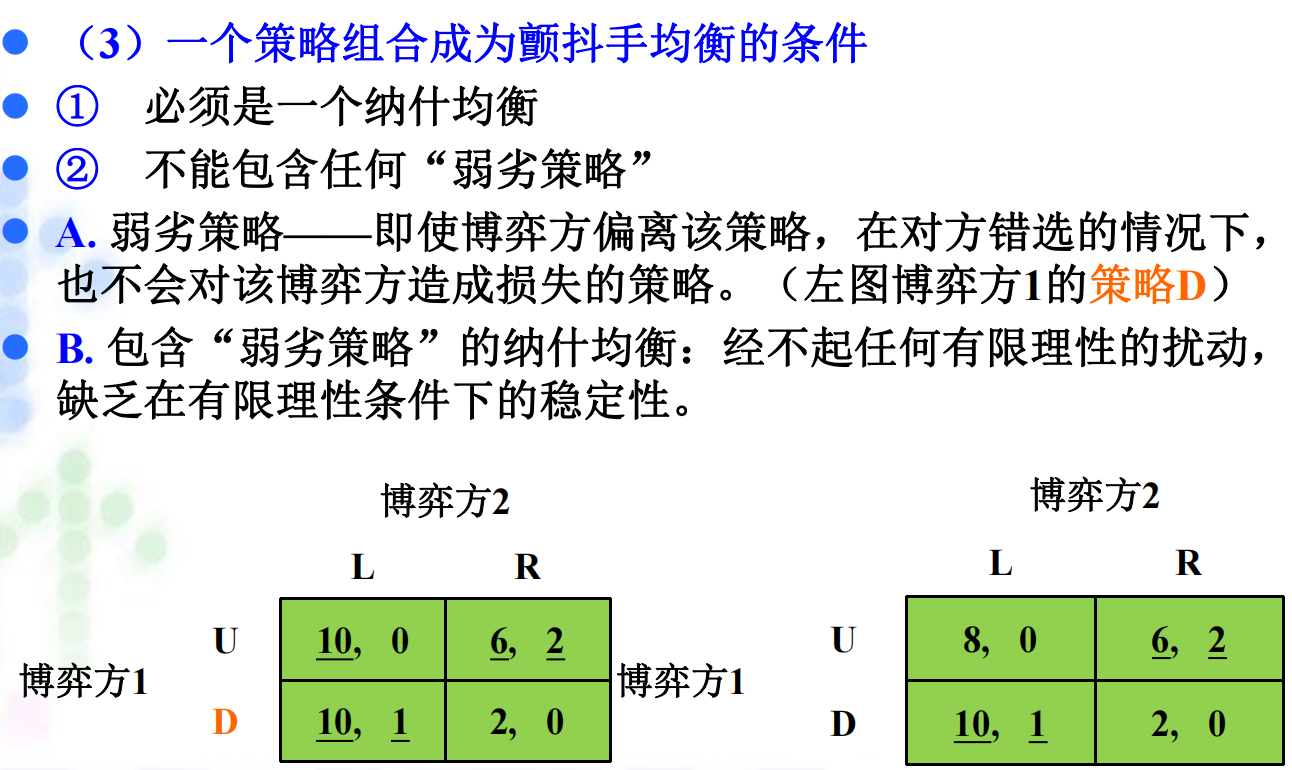
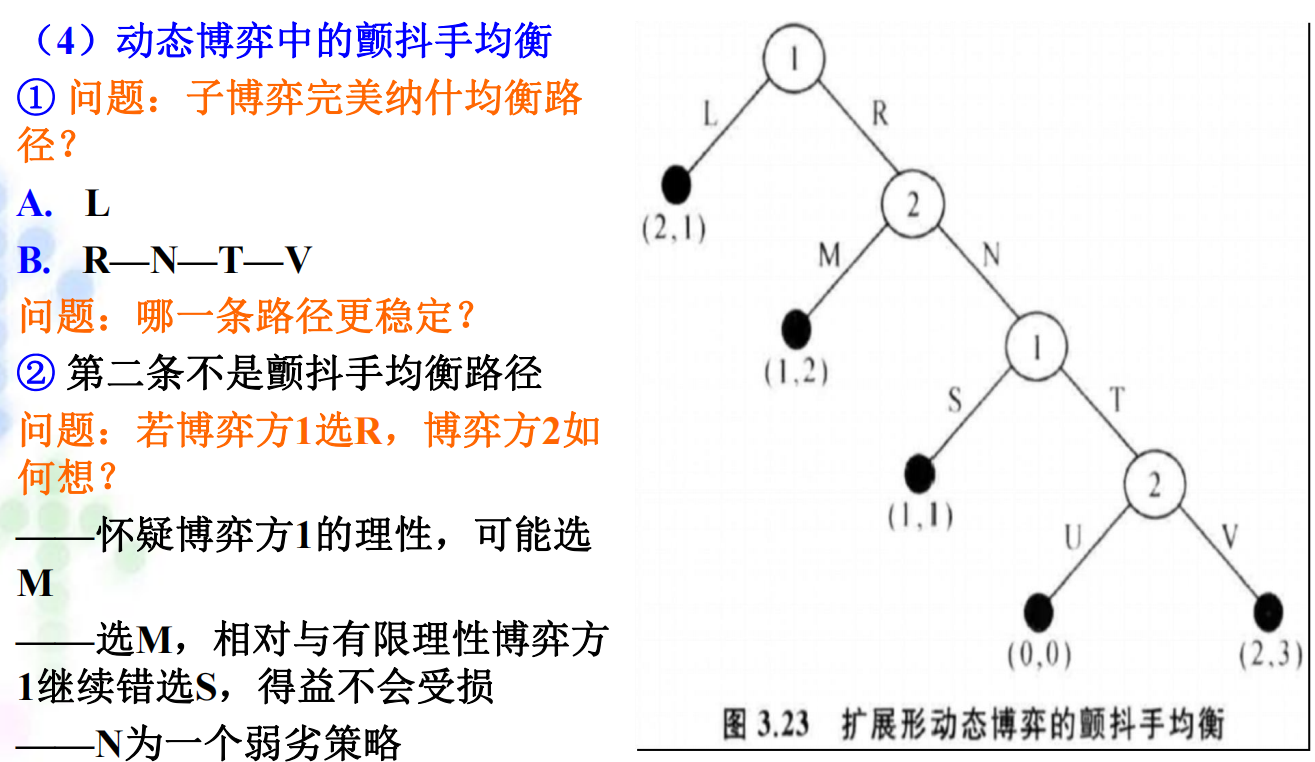
4.3 颤抖手均衡: 由经济学家泽尔腾提出。\(\small{\sout{有趣的是,他的家乡也被一个“颤抖手”给搞丢了}}\)。 定义:假设一个博弈方以小概率偏离了原来的子博弈完美纳什均衡路径,并错选了其他非最优行动,但如果其他博弈方的行动仍能构成对其错选行动的最优反应,且原子博弈完美纳什均衡仍能维持,并且是稳定的,则该子博弈完美纳什均衡被称为颤抖手均衡。
4.3.1 颤抖手均衡条件:
4.3.2 颤抖手均衡的例子:
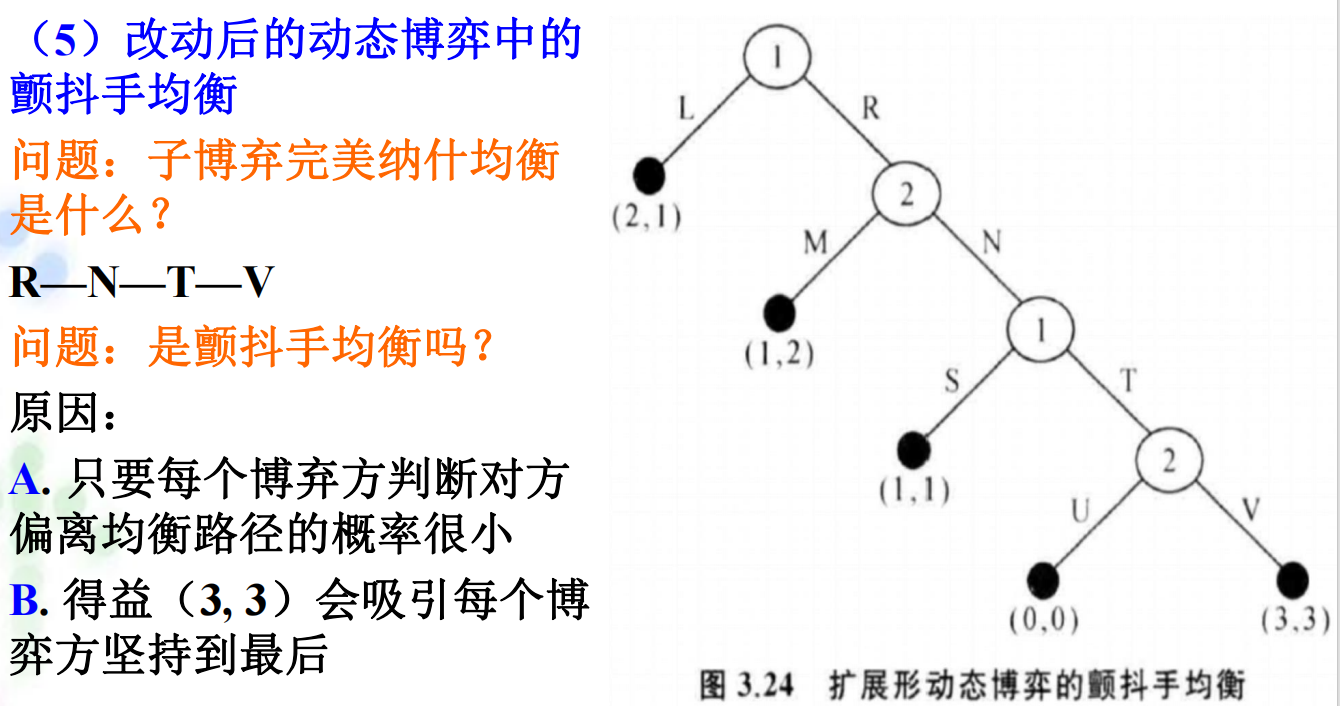
4.4 顺推归纳法:
定义已于1.3中给出。不难看出是精炼纳什均衡的方法,即为有意偏离子博弈完美均衡来追求更高得益提供了方法。比如在蜈蚣博弈和van Damme博弈中。

5. 章节重要简答题汇总