PART 1:深度学习的宏观背景与方法论基础
1. 深度学习(Deep Learning)改变世界
- 计算机视觉 (CV):自动驾驶(目标框选)、监控安防(行人追踪识别)、医疗影像诊断(MRI病灶分析)、图像识别(2015年ResNet在ImageNet超越人类)。
- 自然语言处理 (NLP) & 语音:机器翻译(如AR实时路牌翻译)、个人语音助手(智能音箱/手机)、自然语言理解(2019年多任务学习模型在SQuAD等阅读理解任务上突破)。
- 其他前沿:生成式模型(如GAN实现梵高风格画作生成、真假图像鉴别)、强化学习(2016年DeepMind AlphaGo、2019年OpenAI Dota2击败人类冠军)。
2. 深度学习方法(Deep Learning Approach)
- 定义模型(带参数的函数):构建神经网络 \(\hat{y}_i = f(w, x_i)\)。输入图像 \(x_i\) 经过多层权重参数 \((w_1, w_2, w_3, w_4, w_5)\) 的计算,输出预测类别 \(\hat{y}_i\)。
- 定义优化目标:构建损失函数 \(\min_w L(w) = Loss(\hat{y}_i, y_i)\),计算模型预测结果与真实标签(Ground Truth)之间的误差(Error)。
- 计算梯度并更新参数:利用反向传播将Error从最后一层逐层向前传递求偏导(\(\frac{derror}{dw_5}, \frac{derror}{dw_4}...\)),并使用梯度下降法更新参数:\(w_i \leftarrow w_i - \eta \nabla_{w_i} L(w)\) (\(\eta\) 为学习率)。
PyTorch 代码示例(LeNet):
class LeNet(nn.Module)对应步骤1(定义网络包含Conv2d、Linear等层)。loss = criterion(outputs, targets)对应步骤2(计算误差)。loss.backward()和optimizer.step()对应步骤3(求导与参数更新)。
3. 神经网络发展的历史脉络
- 1940s-1950s (启蒙期):1943年M-P模型实现逻辑门(权重不可学);1957年感知机(Perceptron)引入可学习权重和阈值。
- 1960s (黄金时代):ADALINE模型提出。
- 1969s (AI寒冬):Minsky等人指出单层感知机无法解决 XOR(异或)线性不可分问题。
- 1986s (破冰):多层感知机(MLP)结合反向传播(Backpropagation)算法解决了XOR问题。但受限于计算量大、易陷入局部最优和过拟合,随后被SVM(支持向量机)压制。
- 2006年以后:深度神经网络(DNN)通过分层特征学习(Hierarchical feature learning)重新崛起。
4. 深度学习为何在近十年才获得巨大成功?
核心原因是算法与底层系统的共振进步:
- 海量的标识数据:互联网和商业网站提供了巨量数据(如MNIST只有6万样本,而ImageNet达1400万图像,1000个分类;Web级图片达数十亿)。
- 算法演进:网络结构不断深化(LeNet [1998] -> AlexNet [2012, 16.4%错误率] -> Inception [2015] -> ResNet [2015, 3.57%错误率] -> EfficientNet [2019, 3.1%] -> NAS)。引入了 ReLU、Dropout、Batch Normalization、残差连接等革命性机制。
- 计算能力的摩尔定律打破:CPU算力增长平缓(5 Kops 到 500 Gops),而 GPU(提速 \(10^5\) 倍,如V100 125 Tops)和专用硬件 TPU(提速 \(10^8\) 倍,如TPUv3 360 Tops)带来了海量算力。
- 系统级框架繁荣:TensorFlow、PyTorch、Caffe等框架,结合了编程语言、编译器优化、RDMA通信和分布式系统技术。
PART 2:深度神经网络计算框架(Computation frameworks for DNN)
1. 为什么我们需要深度学习框架?
如果用原生代码(如嵌套for循环)纯手工实现卷积神经网络:
- 问题:难以暴露API给其他用户、难以实现多线程加速、无法轻易运行在GPU上、手动编写后向求导算子极度困难。 换言之,有五大目标
- 前端(面向用户):如何灵活的表达一个CNN模型
- 算子(执行计算):如何保证每个算子的执行性能
- 求导(更新参数):如何自动地提供求导运算
- 后端(系统相关):如何将同一个算子跑在不同的加速设备上
- 运行时:如何自动地优化和调整一个模型的计算
因此,深度学习计算有两个极端的实现方式:
- 极端1(纯高级语言如Numpy实现):极度灵活(Python-like),但每一行操作产生中间变量,计算效率极低。
- 极端2(调用高度优化的黑盒计算库,如xxlib.resnet152):执行效率极高,但只能跑固定网络,毫无灵活性。
深度学习计算框架的目的
- 提供==灵活==的编程模型和编程接口 (简洁的神经网络计算原语编程语言) (提供直观地模型构建方式) (较好的支持与现有生态环境融合)
- 提供==高效==和可扩展的计算能力 (自动计算梯度并完成反向传播) (自动编译优化算法,包括不限于:公共子表达式消除,内核融合,内存布局优化等) (根据不同体系结构和硬件设备自动并行化) (自动分布式化,并扩展到多个计算节点) (持续优化)
2. 第一代计算框架的局限性(以Caffe为代表,-2010)
- 特点:以配置文件的形式(Layer-based)定义网络图。框架为每个Layer提供C++级别的前向/反向实现。
- 三大局限性(导致其被淘汰):
- 灵活性的限制:深度学习快速发展涌现出无数新结构(如Attention、Sampled Softmax),要求开发者每次都要用C++重新硬编码写出复杂的
forward()和backward()函数,迭代太慢。 - 优化器受限:新的优化器(如Adam、带有动量的SGD)需要对梯度和参数进行更通用复杂的数学运算(如 \(w \leftarrow w - (\gamma \nabla_w^{t-1} + \eta \nabla_w^t)\)),死板的Layer结构难以复用这些逻辑。
- 训练模式僵化:基于简单的“前向+后向”模式,难以支持RNN所需的控制流(循环体)、GAN(生成对抗网络)所需的两个网络交替训练、强化学习所需的与外部环境交互。
- 灵活性的限制:深度学习快速发展涌现出无数新结构(如Attention、Sampled Softmax),要求开发者每次都要用C++重新硬编码写出复杂的
PART 3:现代深度学习框架的核心底层机制
(注:第二代框架指 TensorFlow, PyTorch, MindSpore, MegEngine 等,2015年至今)
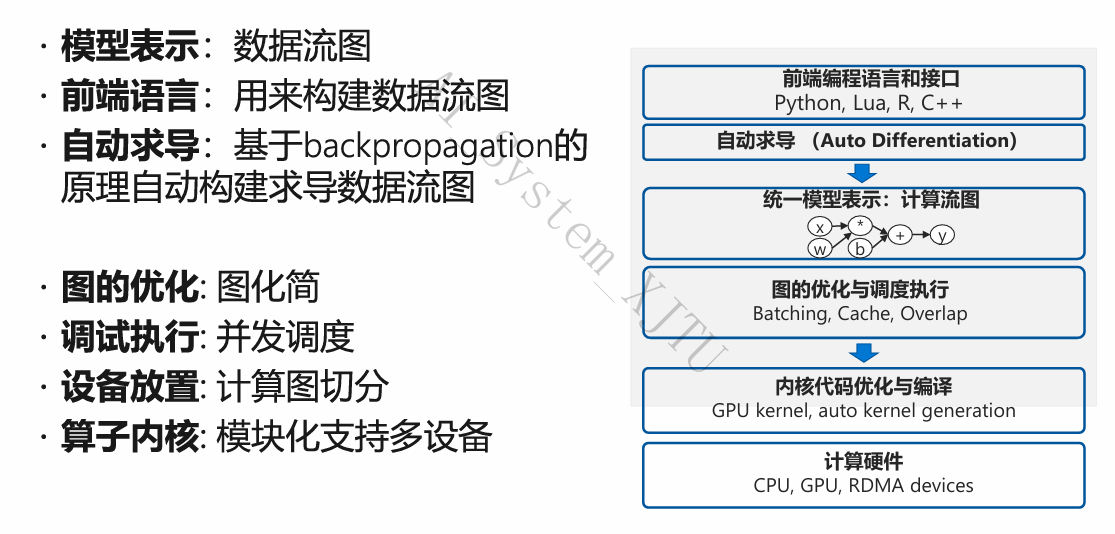
一、统一的模型表示 —— 数据流图(DAG)
现代框架将复杂网络抽象为有向无环图(DAG):
- Tensor(张量/数据):多维数组(包含形状、类型如int/float)。在图中表示为“边(Edges)”,在节点间流动。
- Operator(算子/计算):最基础的代数运算单元(加减乘除、Conv、Relu、MatMul等,TF中有>400个)。在图中表示为“节点(Nodes)”**。
- Variable/参数:计算的状态(权重参数)也作为特殊的Operator存在。
- 控制流:引入了特殊算子(Switch, Merge, While)和不传递数据的 控制边(Control Edges) 来表达执行依赖。
二、数据流图类型(静态图 vs 动态图)
| 维度 | 静态图 (Static Graph / Define-and-run) | 动态图 (Dynamic Graph / Define-by-run) |
|---|---|---|
| 代表框架 | 早期 TensorFlow | PyTorch |
| 运行机制 | 先定义后执行:程序编译时先不计算,而是生成一张完整的图结构网络,随后再喂入数据(feed_dict)让数据在建好的图中运行。 | 边定义边执行:程序严格按照Python代码顺序逐行执行。每次前向计算都在构建一个崭新的图。 |
| 优点 | 1. 框架能看到全局信息,可进行极致的全局图优化,计算效率高。 2. 能准确分析张量生命周期,内存使用效率极高。 |
1. 代码极度简洁,可实时print出计算结果,易于调试。2. 拥有极高的可编程性,完美兼容Python原生的if/while控制流。 |
| 缺点 | 1. 无法实时获得中间结果,调试像做黑盒测试。 2. 对于带有复杂控制流的网络支持非常不友好。 |
1. 缺乏全局视野,无法进行全图预先化简优化。 2. 无法进行全图精确的内存分配预管理。 |
三、深度计算的核心 —— 自动求导(Auto Differentiation, AD)
求导是更新参数的前提。对比几种求导方式:
- 符号求导 (Symbolic):利用导数公式(即数学中常用的各种求导公式、算子等)进行精确数学推导。缺点:稍微复杂的函数就会导致表达式指数级膨胀。
- 数值求导 (Numerical):利用极限公式 \(\frac{f(x+h)-f(x)}{h}\) 计算近似值。缺点:存在截断误差;无法处理不可导的算子(如ReLU、Switch的拐点)。
- 自动求导 (Auto Differentiation - 框架采用的方法):
- 原理:将复杂函数拆解为基本算子的组合(形成数据流图)。例如 \(L(x) = \exp(\exp(x) + \exp(x)^2) + \dots\),拆分为 \(a=\exp(x), b=a^2, c=a+b \dots\)
- 过程:前向传播时计算并保留所有中间变量的结果(建构前向图);反向传播时,严格遵循链式求导法则(Chain Rule),依次从后往前计算偏导数(如 \(\frac{df}{dc} = \frac{df}{dd}\exp(c) + \frac{df}{de}\cos(c)\))。
- Core:框架将导数的计算过程,也直接表示成一张数据流图(反向图) 这意味着导数计算图同样可以享受全局图优化和内存分配带来的效率提升。

四、图优化技术 (Graph Optimization)
在“先定义后执行”模式下,框架在正式运算前会做“图化简”动作(Pass):
- 基础优化:表达式化简、公共子表达式消除、常数传播(如
a=2*3直接被替换为a=6的常数节点)。 - 进阶优化(算子融合 Operator Fusion/Batching):
- 极佳案例(PPT P40-41):在RNN/GRU模型中,含有多个独立的、小规模的矩阵乘法操作(如输入 \(x_t\) 分别乘以权重 \(W_f, W_o, W_z\))。
- 框架会自动将这些同类型的操作(MatMul)在维度上拼接(Concat),自动融合为一个超大矩阵乘法(GEMM)。
- 目的:最大程度压榨利用 GPU 这种适合海量并发计算的硬件特性(Leverage GPU massive parallelism)。
五、调度、并发执行与分布式设备放置 (Device Placement)
- 并发调度:框架根据DAG图的拓扑排序,发现哪些节点没有依赖关系(相互独立)。将这些独立算子放入“并发执行队列”中,多线程同时丢给GPU执行,执行完后自动激活后续节点。
- 设备放置与图切分:
- 用户可以显式指定运算设备(如 TensorFlow 中的
with tf.device('/gpu:0'):和/gpu:1)。 - 当数据流图的“边(Tensor)”跨越了不同设备(如 Server 0 计算完的结果需要传给 Server 1),框架会自动将这条边切断,并在两端分别插入一对特殊的
Send和Recv算子。 - 效果:实现了跨设备的张量透明传输(Transparent tensor transmission mechanism),极大降低了分布式集群编程的难度。
六、计算内核(Kernel)与多硬件支持
- Kernel 定义:是一个算子在某种具体设备上的底层代码计算实现。
- 多态注册:一个独立的Operator(比如 Conv 算子)可以注册 N 个 Kernel:
- 按硬件分:GPU kernel (CUDA编写), CPU kernel (C++编写), ASIC kernel, FPGA kernel。
- 按数据类型分:float32 kernel, int kernel, half (FP16) kernel。
- 根据Operator属性不同也可以有多种kernel
- 运行时决策:在代码运行时,框架会自动根据设备类型和张量数据类型,动态分发选择最高效的 Kernel 去执行。
七、小结
PART 4:计算框架的未来发展趋势
随着深度学习模型规模的指数级爆发(如大语言模型),框架面临更加多元化和极限的挑战,演进趋势包括:
- 基于编译器的算子优化 (Deep Learning Compilers): 过去框架极度依赖底层库(如 cuDNN)和工程师手动调优 Kernel。未来的趋势是利用 AI 编译器技术,降低对人工调优的依赖,“只要开发一次模型,就能通过编译器自动为任何陌生/异构硬件生成最优化的机器执行代码”。
- 动态图和静态图走向统一 (Unification):
业界正在努力打破鸿沟,实现“既要又要”。即:前端支持动态图的灵活编程体验(方便调试),但在后台通过即时编译技术(JIT)或特定修饰符(如 PyTorch 的 TorchScript /
torch.compile)将其智能转化为静态图去执行,以兼顾极致的运行性能。 - 应对超大规模网络训练范式: 百亿/千亿级大模型对当前AI框架的单点性能、显存极限管理、多机多卡海量通信、网络调优、分布式部署提出了全方位的挑战,促使框架衍生出更多的并行策略(数据并行、张量并行、流水线并行等)。