核心
AI系统 = 算法 + 算力 + 数据(算例) + 框架
- 算法进步:从 VGG-19 -> 34-layer plain -> 34-layer residual (ResNet)。
- 海量数据:如 ImageNet (14M 图像数据)。
- 计算能力:NVIDIA Volta GPU, FPGA, Graphcore, RDMA, NVLink 技术。
- 深度学习框架:TensorFlow, Microsoft CNTK, Caffe2, DMLC mxnet, PyTorch。
四大模块:
- 神经网络模型搭建 (Lenet)
- 定制数据集 (Dataset & Dataloader)
- 使用服务器 (Linux, Vim, GPU 环境配置)
- 训练过程可视化 (TensorBoard)
🧱 模块一:神经网络模型搭建
1. 卷积神经网络基础 (CNN)
1.1 LeNet 架构
- 地位:最早的卷积神经网络,是一个基础的前向传播网络(接受输入 -> 经过层层传递计算 -> 得到输出)。
- 流程:输入 (Input) -> 特征提取 (Convolutions + Subsampling/Pooling) -> 分类识别 (Full connection + Gaussian)。
- PyTorch 接口:
torch.nn是 PyTorch 专门为神经网络设计的模块化接口,其底层基于 AutoGrad (自动求导) 实现。
1.2 为什么用 CNN?
- 全连接网络 (Fully Connected):每个神经元与前一层所有神经元相连,会导致参数量爆炸(如 1000x1000 图像会产生 \(10^{12}\) 参数)。
- 局部连接网络 (Locally Connected/CNN):利用图像的局部空间相关性 (Spatial correlation is local)。使用共享的卷积核(Filter,如 10x10),大幅减少参数量(降至 100M 参数),将计算资源用在更重要的地方。
1.3 CNN 的基础结构与 PyTorch 实现
- 卷积层 (Convolution):
- 作用:多通道特征提取。包含 Padding (边缘填充) 和 偏置项 (Bias)。
- 代码:
self.conv1 = nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5) - 池化层 (Pooling):
- 作用:降维,保留最重要特征。
- Max Pooling (最大池化):在指定窗口(如2x2)内取最大值。例如输入
[[1,1],[4,6]]-> 输出6。 - Average Pooling (平均池化):在指定窗口内取平均值。例如上述输入 -> 输出
3。 - 代码:
self.mp = nn.MaxPool2d(kernel_size=2) - 全连接层 (Fully-connected):
- 代码:
self.fc = nn.Linear(in_features=N, out_features=10) - 多层感知机 (MLP):
- 包含:Input layer (输入层 \(x\)) -> Hidden layer (隐藏层 \(y\)) -> Output layer (输出层 \(z\))。
2. Pytorch 神经网络搭建
定义网络时,必须继承 nn.Module。
nn.Module 是一个网络的封装,包含各层定义及前向传播方法。
2.1 构造函数 __init__(self)
- 必须先执行
super(Net, self).__init__(),初始化继承自父类的所有属性和方法。 - 核心准则:把网络中具有“可学习参数”的层(如 Conv2d, Linear)全部定义在构造函数中。
2.2 前向传播函数 forward(self, x)
- 对输入
x依次进行:卷积 -> 激活 (ReLU) -> 池化 操作。 - 激活函数:
F.relu()(不含学习参数,直接在 forward 中调用)。 - 反向传播:定义完前向传播后,反向传播函数会根据
autograd自动实现,无需手动编写。 - 张量展平 (Flattening):
- 在进入全连接层前,必须将多维特征图展平为一维向量。
- 使用
x.view(in_size, -1):改变 tensor 的形状,但元素总数不变。-1代表该维度的尺寸由计算机自动推导。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10) # 320 需要根据前面池化后的维度计算得出
def forward(self, x):
in_size = x.size(0) # 获取 batch_size
x = F.relu(self.mp(self.conv1(x)))
x = F.relu(self.mp(self.conv2(x)))
x = x.view(in_size, -1) # flatten the tensor 展平
x = self.fc(x)
return F.log_softmax(x)
3. 经典复杂网络搭建:GoogLeNet 与 ResNet
3.1 GoogLeNet & Inception Module
- 核心:通过
Inception Module并行使用不同尺寸的卷积核 (1x1, 3x3, 5x5) 和池化层,最后将结果在通道维度拼接 (Filter concat)。 - 1x1 卷积核的妙用:Scaling (缩放通道数)。主要用于降维,减少后续计算量。
- 代码实现:分别构建 4 个平行的 branch。
branch1x1: 直接过一个 1x1 卷积。branch5x5: 先过 1x1 卷积降维,再过 5x5 卷积 (padding=2保持图像尺寸)。branch3x3dbl: 先过 1x1 卷积,再过两个 3x3 卷积 (padding=1)。branch_pool: 先平均池化 (F.avg_pool2d),再过 1x1 卷积升维。- 最终输出合并:
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]。
3.2 ResNet (残差网络)
- 核心思想:引入残差连接 (Shortcut Connection),解决网络过深导致的梯度消失和退化问题。
- 残差块 (Residual Block) 两种模式:
BasicBlock:适用于 ResNet-18 和 ResNet-34。Bottleneck:适用于更深的网络(ResNet-50 及以上)。
- 代码实现:
- 在
forward函数最后,将输入直接加到输出上:out += identity。 - 网络组装 (
_make_layer):以循环方式调用残差块,组成残差模块。for _ in range(1, blocks): layers.append(block(...)) - 实例化模型:使用一个四元素列表
layers分别表示 4 个大层中残差块的个数。例如model = ResNet(BasicBlock, [3, 4, 6, 3])对应的是 ResNet-34。
📁 模块二:定制数据集
1. 数据的加载与预处理工具:torchvision
PyTorch 提供 torchvision 简化了数据加载。内部自带 Imagenet, CIFAR10, MNIST 等数据集。
- 数据转换 (
transforms): - 原始输出的是
[0,1]范围的 PIL 图像。 transforms.ToTensor():将 Numpy 或 PIL 格式图像转换为 PyTorch 支持的 Tensor 格式。transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)):通过归一化将图像数值转换为[-1, 1]之间。- 数据加载器 (
DataLoader),进行三项工作:- 批处理数据 (
batch_size=4)。 - 打乱数据 (
shuffle=True针对训练集,测试集一般为 False)。 - 并行加载 (
num_workers=2):使用 multiprocessing 并发读取,极大提升效率。
- 批处理数据 (
2.Insight:生成定制数据集
面对大规模自定义数据,不能一次性全部读入内存,必须自定义 Dataset。
- 准备工具:
- 依赖库:
scikit-image(图像读写和转换),pandas(解析 CSV 标签文件)。 - 标注工具:
labelImg(用于目标检测手工标注,命令行执行$ pip install labelimg及$ labelImg启动)。 - 重写法则:自定义类必须继承
torch.utils.data.Dataset,并严格重写以下 3 个函数:__init__(self, csv_file, root_dir, transform=None):初始化,读取 CSV 文件路径及图像根目录。__len__(self):让len(dataset)能够返回整个数据集的大小(样本总数)。__getitem__(self, idx):【优化】 用来支持索引切片dataset[i]。它的机制是按需读取(懒加载),只在用到第 \(i\) 个样本时才从硬盘读取该图像,避免内存溢出。
3. 生成定制的 Transforms (数据增强)
因为神经网络需要固定大小的图像输入,且需要做数据增强,所以需要自定义 Transform 类。
- 3个常用自定义 Transform 类:
Rescale:缩放图像尺寸到固定大小。RandomCrop:随机裁剪图像,进行数据增强 (Data Augmentation)。ToTensor:转换格式并交换维度 (Numpy 的 HxWxC 转换为 PyTorch 的 CxHxW)。
- 代码实现:
- 将操作写成可调用的类 (Callable Class),不必每次调用都传参。
- 需要在类中重写
__init__(接收超参数) 和__call__(执行具体变换逻辑) 方法。 - 组合调用:通过
transforms.Compose([Rescale(256), RandomCrop(224), ToTensor()])将多个操作串联。
🖥️ 模块三:使用服务器
1. Linux 与 Vim 基础
- Why Linux?:开源共享精神;完美兼容 GPU、TensorFlow、PyTorch 等框架。
- “Windows 是文案者的 OS,Mac 是设计者的 OS,Linux 是开发者的 OS。”
- Vim 文本编辑器:
- Linux 哲学:“一切都是文件”。配置服务即修改文件参数。Vim 是最高效的工具。
- 三种核心模式及切换:
1. 命令模式 (默认):按
Esc退回。 2. 输入模式:在命令模式下按a(后方插入),i(前方插入),o(换行插入) 进入。 3. 末行模式:在命令模式下按:进入。 - 命令模式高频快捷键:
dd: 删除(剪切)所在整行 。5dd: 删除下方5行。yy: 复制所在整行 。5yy: 复制下方5行。p: 粘贴到光标后。u: 撤销上一步。n/N: 搜索时跳到 下一个 / 上一个 匹配项。
- 末行模式高频快捷键 (
:)::w(保存),:q(退出),:wq!(强制保存退出),:q!(放弃修改强制退出)。:set nu(显示行号),:set nonu(隐藏行号)。:<整数>(跳转到对应行)。:s/one/two/g(当前行将 one 替换为 two) /:%s/one/two/g(全文所有 one 替换为 two)。/字符串(从上至下搜索)?字符串(从下至上搜索)。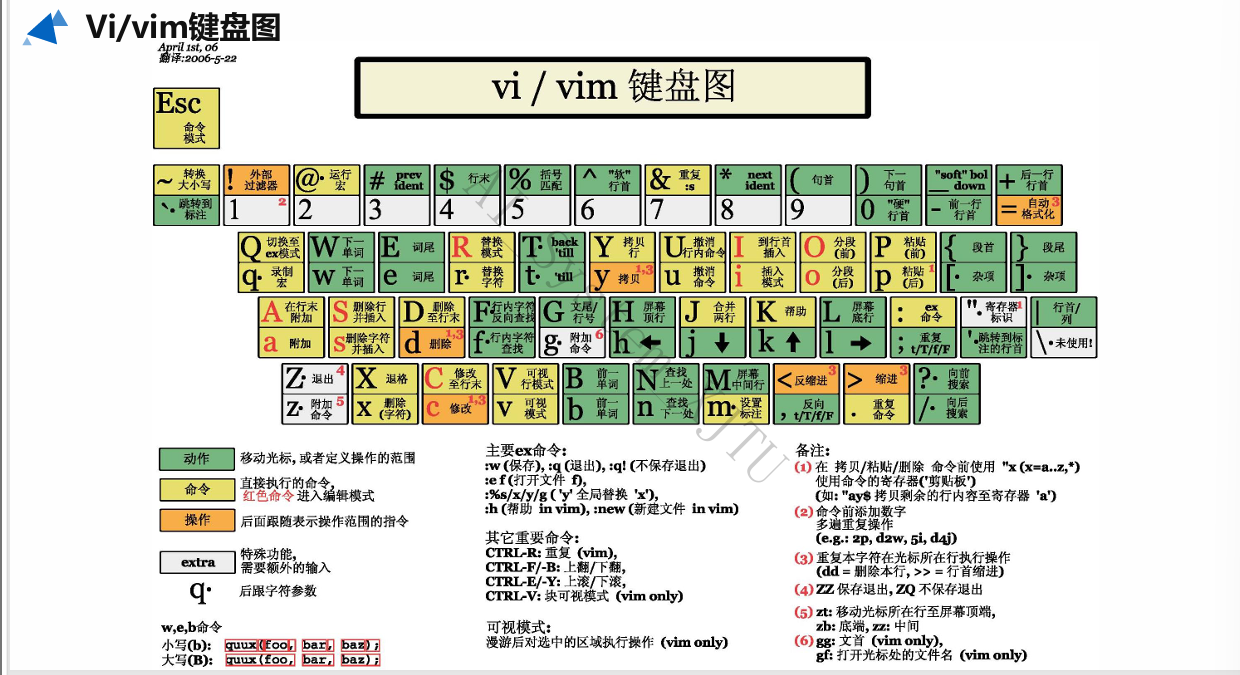
2. GPU 深度学习环境配置架构
由于卷积网络包含大量并行计算,必须使用 GPU 加速。配置层级自下而上如下:
Step 1. 显卡驱动 (Nvidia Driver)
- 作用:监控显卡使用情况的必要软件。
- 安装 (Ubuntu PPA):
sudo apt-get install nvidia-driver-410 - 验证命令:
$ nvidia-smi(极其重要,用于查看显卡 PID、利用率、显存 Memory Usage)。
Step 2. 运算架构 (CUDA)
- 作用:Compute Unified Device Architecture。NVIDIA 推出,包含指令集架构 (ISA) 和并行计算引擎,使 GPU 能处理复杂计算问题(基于 C++)。
- 配置:安装后必须在
~/.bashrc中写入环境变量: export PATH=/usr/local/cuda-10.0/bin${PATH:+:${PATH}}export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64...- 验证命令:
$ nvcc -v。
Step 3. 加速库 (cuDNN)
- 作用:专门针对深度神经网络的 GPU 加速库,强调高性能与低内存开销。
- 安装机制:即简单的“插入式设计”。下载
.tar压缩包解压后,直接使用cp命令将其头文件 (cudnn.h) 放入 CUDA 的include目录,将库文件 (libcudnn*) 放入 CUDA 的lib64目录,赋予读权限 (chmod a+r) 即可。(也可使用.deb通过dpkg -i安装)。
Step 4. 环境隔离工具 (Anaconda) & 框架 (PyTorch)
- 作用:管理 Python 版本和包,形成各自隔离的沙箱环境,互不冲突。
- 常用 Conda 命令:
$ conda init(写入 .bashrc)$ conda info --envs(查看所有环境)$ conda create -n py37 python=3.7.6(新建名为 py37 的环境)$ conda activate py37(激活环境)- 安装 PyTorch:使用
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch或pip install对应版本。
📈 模块四:训练过程可视化 TensorBoard
1. 为什么用 TensorBoard?
- Old fashion:疯狂
print数据,满屏浮点数,完全无法直观看出 loss 下降趋势或过拟合。 - New way (TensorBoard):原本是 TensorFlow 的可视化套件(PyTorch 现已原生兼容)。能够实现:
- Visualize TF graph:可视化网络拓扑计算图。
- Plot quantitative metrics:绘制标量折线图(如 Loss, Accuracy)。
- Show additional data:显示直方图(权重、偏置分布)、图像等。
2. 使用 TensorBoard 的 5 个步骤
- 决定要记录的张量 (Decide tensors to log):
- 标量 (Scalar, 适用于 Loss/Acc):
cost_summ = tf.summary.scalar("cost", cost) - 高维张量/直方图 (Histogram, 适用于权重/偏置监控分布):
w2_hist = tf.summary.histogram("weights2", W2) - 优化技巧 (Slide 61):使用
with tf.name_scope("layer1"):给代码分块,这样在 TensorBoard 的 Graph 面板中会生成更清晰、具有层级结构的图。
- 标量 (Scalar, 适用于 Loss/Acc):
- 合并所有的 Summaries:
summary = tf.summary.merge_all()
- 创建 Writer 并将计算图写入:
writer = tf.summary.FileWriter('./logs')writer.add_graph(sess.graph)
- 在训练循环中运行并添加 Summary:
s, _ = sess.run([summary, optimizer], feed_dict=feed_dict)writer.add_summary(s, global_step=global_step)
- 在终端启动 TensorBoard:
$ tensorboard --logdir=./logs
3. 启动并查看 TensorBoard (本地与服务器端口映射)
- A:本地 PC 端启动
- 终端运行:
$ tensorboard --logdir='./runs/xxx' - 浏览器访问:
http://127.0.0.1:6006即可。 - B:远程服务器端启动 ( 重点:端口映射) 当代码在没有图形界面的远程服务器上训练时,如何用本机的浏览器查看?
- Step 1:使用 Telnet/SSH 工具连接远端 Server。正常用
python3运行包含 writer 的训练脚本,随后在服务器端敲击$ tensorboard --logdir='./runs/xxx'开启进程(此时默认监听服务器的 6006 端口)。 - Step 2:在本地电脑上,打开一个新的 Terminal Tab,执行端口映射 (Port Forwarding)命令:
$ ssh -L 7007:localhost:6006 iair270@115.154.142.79(参数拆解:-L 本地端口:localhost:服务器远端端口 远端账号@远端IP。此命令意为将本地电脑的 7007 端口,通过 SSH 隧道,映射到远程服务器的 6006 端口) - Step 3:在本地电脑的浏览器中输入地址:
http://localhost:7007(或127.0.0.1:7007),即可查看服务器上的训练动态图表。