🎯 导言
深度学习(CFC CNN RNN Attention) \(\Rightarrow\) 矩阵运算(矩阵乘法 向量乘法 线性代数运算 矩阵分解) \(\Rightarrow\) 体系结构(依托 CPU/GPU/ASIC 等体系结构进行极致加速)。
PART 1:深度学习常见模型
深度学习算法有很多种,但在计算机底层,它们统统被抽象为矩阵乘法 (GEMM)、向量乘法等。
1. 四大经典网络层的矩阵化解析
- 全连接层 (Fully Connected Layer / MLP)
- 架构特征:前向全连接层,每个输出神经元与所有输入神经元相连。
- 数学本质:从标量公式 \(y_3 = \sum_{i=0}^{2} x_i w_{i,3}\) 进化。
- 矩阵映射:设输入为列向量 \(X = [x_0, x_1, x_2]^T\),权重为矩阵 \(W\)。其计算被完美映射为矩阵乘法:\(Y = W^T X\)。
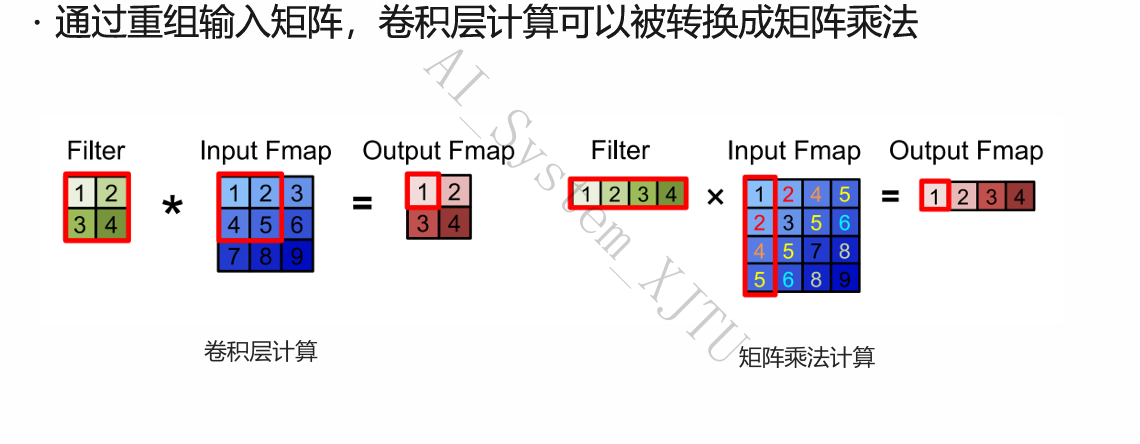
- 卷积层 (Convolution Layer / CNN)
- 架构特征:常用于图像任务,利用滤波器 (Filter) 在输入特征图 (Input Fmap) 上执行滑动窗口 (Sliding Window) 逐元素乘加计算。
- 矩阵映射(核心重组技术):传统的滑动窗口极难利用硬件并行。系统通过内存重组技术(类似 Im2Col 操作),将三维的输入特征图和卷积核展平。
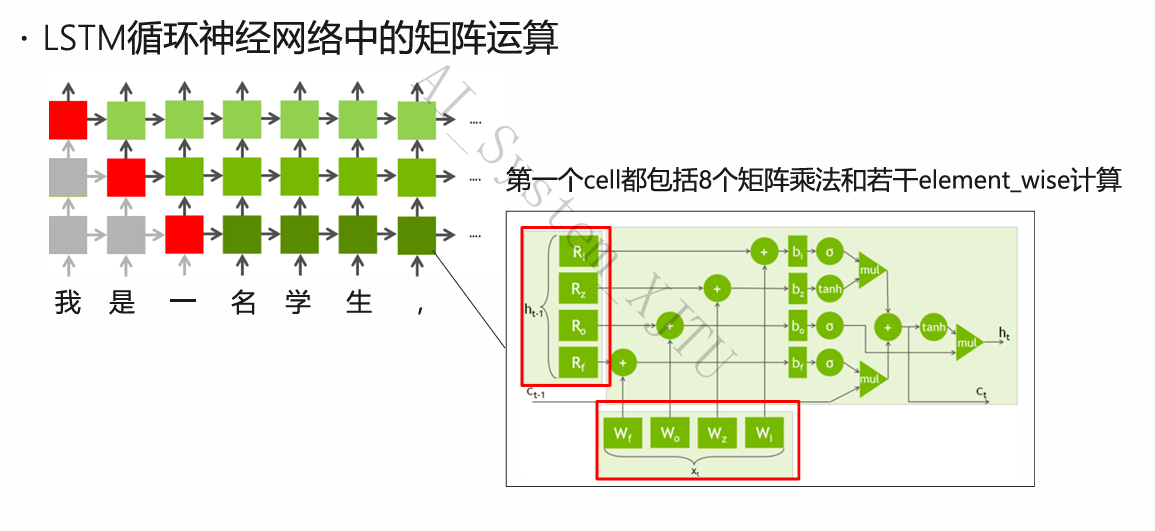
- 循环网络层 (RNN / LSTM)
- 架构特征:用于处理有时间顺序的序列数据(如语音处理、自然语言处理 NLP)。
- 矩阵映射:PPT中展示了 LSTM 的内部 Cell 架构。即使是仅仅计算一步(即一个 Cell),其内部的四个门限(输入门、遗忘门、输出门等)就直接包含了 8 个不同的矩阵乘法操作(涉及输入权重矩阵 \(W_f, W_o, W_z, W_i\) 和隐状态权重矩阵 \(R_i, R_z, R_o, R_f\)),并伴随 tanh/sigmoid 等 element-wise 操作。
- Attention网络层 (Transformer / BERT)
- 架构特征:Transformer 网络的主要结构,是目前大模型 (LLM) 的基石。
- 矩阵映射:当前主流的Attention机制(Scaled Dot-Product Attention)的全流程均为矩阵运算:输入映射生成 \(Q, K, V\) 矩阵 \(\rightarrow\) \(Q\) 与 \(K\) 矩阵相乘 (MatMul) \(\rightarrow\) 缩放与 SoftMax \(\rightarrow\) 概率矩阵再与 \(V\) 矩阵相乘 (MatMul)。
2. Question:为什么神经网络一定要表示成矩阵计算?
- 极高的计算并行性:矩阵计算的数据依赖性极弱,每个元素的内积可以同时独立发生。
- 硬件与软件的现成生态:计算机科学发展数十年,针对矩阵运算有最成熟的加速硬件(CPU/GPU)和最底层的软件库(MKL, CuBLAS, BLAS)。
- 双向驱动(鸡生蛋效应):因为底层硬件算矩阵快,所以算法专家倾向于设计以矩阵为主的网络;因为深度学习全用矩阵,硬件厂商(如Nvidia, Google)拼命迭代只为优化矩阵算力,形成正向循环。
PART 2:并行处理硬件架构
要理解 CPU 和 GPU 的区别,必须从计算机指令流和数据流的分类入手:
- SISD (单指令流单数据流):
- 原理:每个指令部件每次仅译码一条指令,操作部件仅处理一份数据。
- 特点:纯串行计算,硬件本身不支持并行。在一个时钟周期内,CPU 只能处理一条数据流。
- SIMD (单指令流多数据流) 【重点】:
- 原理:一个控制器同时控制多个处理器 (PU)。对一组数据(如数组/向量)中的每一个元素,同时执行完全相同的操作。
- 特点:这是 CPU 向量化指令和 GPU 运算的基础,专为矩阵/科学计算诞生。其性能上限受限于计算机内存的通讯带宽。
- MISD (多指令流单数据流):
- 多个指令流处理同一个数据,作为理论模型存在,基本无实际商业应用。
- MIMD (多指令流多数据流):
- 在多个不同的数据集上,执行多个不同的指令。现代多核 CPU 集群的典型架构。
PART 3:CPU 体系结构与矩阵运算
1. CPU 的物理架构特征与内存层级
- 架构组成:CPU 的硅片面积被巨大的控制单元 (Control) 和庞大的缓存 (Cache) 占据,真正的计算单元 (ALU) 占比很少。
- 强项与弱项:极其擅长处理复杂的控制逻辑(单线程)、分支预测、推测执行、乱序执行。但计算密度低,理论吞吐量存在上限。
- 内存架构(极其关键的时钟周期数据):CPU 采用极深的内存架构来掩盖读写延迟,依靠硬件预取(Prefetch)机制搬运数据。
- Registers (寄存器):512 Bytes 容量,速度 1 周期 (cycle),成本极高。
- L1 Cache:32 KB 容量,速度 2 周期。
- L2 Cache:512 KB 容量,速度 10 周期。
- Main Memory (DRAM 主存):32 MB 容量,速度高达 100 周期(极慢)。
2. CPU 的优化:SIMD 向量化指令集 (SSE/AVX)
- 标量计算的问题:传统执行包含 Fetch (取指) \(\rightarrow\) Decode (译码) \(\rightarrow\) ALU (执行) \(\rightarrow\) Write back (写回)。如果处理 1000 个数据,就要浪费时间做 1000 次相同的 Fetch 和 Decode。
- SIMD 的用法:一条指令,一次译码,驱动多个 ALU 对一组数据同时运算。
- SSE 级 (128-bit 寄存器):可一次塞入 4 个 32-bit Float 或 2 个 64-bit Double。
- AVX 级 (256-bit 寄存器):可一次塞入 8 个 32-bit Float 或 4 个 64-bit Double 并发计算。
3. CPU 上的矩阵乘法优化 (\(C = A \times B\))
- 最直观的实现:三层嵌套
for循环(外层遍历行,中层遍历列,内层做点积累加)。 - 致命性能缺陷剖析:
- 矩阵 A 的问题(计算低效):A 是按行遍历,内存地址连续,完美契合 Cache line(空间局部性极佳)。但如果不用 SIMD,单个数据运算仍然低效。
- 矩阵 B 的问题(访存灾难):C/C++ 中矩阵是按行存储的,但算法需要对矩阵 B 进行按列访问。每次读取仅命中 Cache line 中的一个有效数据,导致海量的 Cache Miss,CPU 被迫频繁向慢速的主存(100 cycles)请求数据。
- 优化方案(代码+硬件):
- 解决 A 的低效:使用 AVX 指令。通过
Broadcast将矩阵 A 的单个元素广播填满整个 SIMD 寄存器,然后与 B 的一整行进行向量化乘加。 - 解决 B 的低效:提高 Cache 命中率。方案包括对矩阵 B 提前进行转置 (Transpose),或者使用矩阵分块技术 (Tiling),将庞大的矩阵切割成正好能塞入 L1 Cache 的小块。
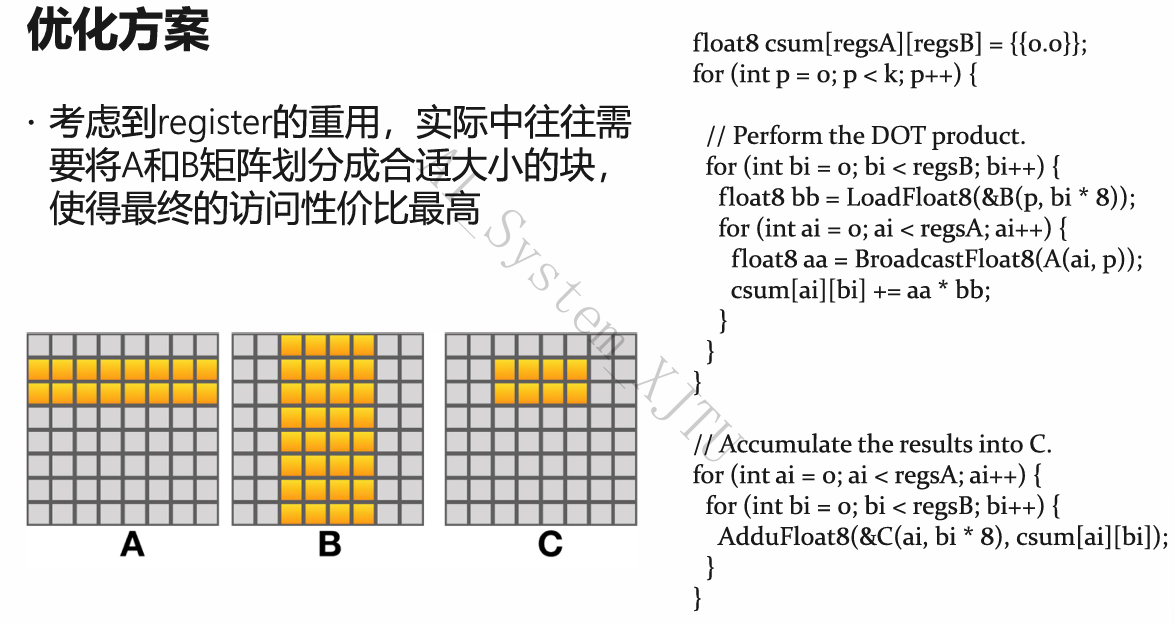 尽可能充分使用寄存器:如 PPT 代码所示,在最内层建立
尽可能充分使用寄存器:如 PPT 代码所示,在最内层建立 csum[ai][bi]寄存器数组,将累加计算全部在 1 cycle 速度的寄存器中完成,直到该块算完,才写回内存。
- 解决 A 的低效:使用 AVX 指令。通过
- 结论:CPU 极致优化涉及流水线、多核、Tiling、AVX 汇编,极其复杂。实际工业界直接调用成熟的 Intel MKL 或 OpenBLAS 库。
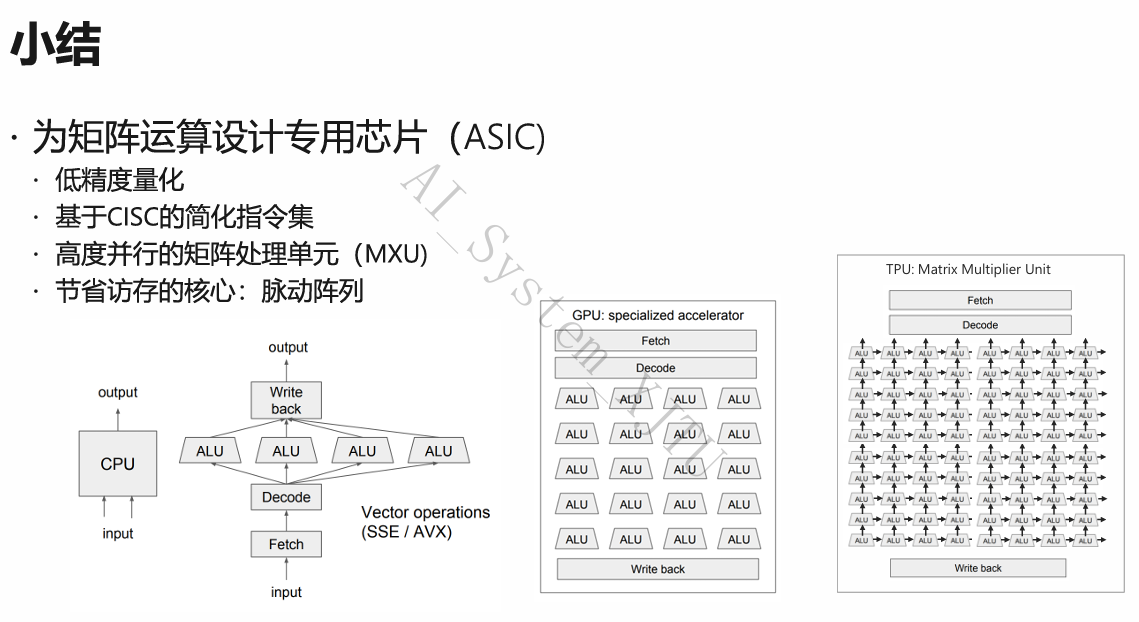
4.小结
- CPU核心的组成
- 计算单元与控制单元
- 内存架构
- CPU上高效矩阵计算
PART 4:GPU 体系结构与矩阵并行
1. GPU 的底层硬件解构
- 架构特征:与 CPU 相反,GPU 内部有上千个极度精简的核心 (CUDA Cores)。控制单元被压缩到了极致。
- 强项与弱项:拥有无与伦比的计算密度和高并发访存能力。非常擅长极其规则、稠密的数据并行计算。不支持分支预测和乱序执行,遇到 if-else 复杂控制流性能会雪崩,也即不擅长处理控制逻辑复杂的程序。

2. GPU执行模型:SIMT (单指令多线程)
- 数个 Cores 组成一个簇(SM, Streaming Multiprocessor)。
- Warp (线程束) 是 GPU 执行的最小原子单位,固定包含 32 个线程。
- 这 32 个线程在同一个时钟周期内,由指令调度器 (Warp Scheduler) 喂给同一条指令,但它们分别在不同的数据内存地址上执行。
3. GPU 的难题:Memory Wall (内存墙)
GPU 算力虽强,但必须面对比 CPU 更严苛的访存延迟(基于 Nvidia Maxwell 架构数据):
- Registers (寄存器):0 周期 / 读后写约 20 周期。
- Shared Memory (共享内存/L1):28 周期。(这是开发者能手动控制的片上极速内存,是优化的核心)。
- L2 Cache:200 周期。
- Global Memory (DRAM 主显存):高达 350 周期。
4. GPU 矩阵乘法的高效实现路径:层级 Tiling (分块) 复用
核心心法:提高访存计算比,让数据每从 Global Memory 搬出一层,就尽可能地多复用数据。
- 第 1 层划分:Thread Block Tile (Block 级块)
- 将巨大的矩阵 A 和矩阵 B 拆成 Block 块。
- 从极慢的 Global Memory 中读取这块数据,存入极快的 Shared Memory 中。该 Block 内的成百上千个线程现在可以共享读取这些数据,极大减少了外部带宽占用。
- 第 2 层划分:Warp Tile (Warp 级块)
- 在 Shared Memory 内部继续划分,将更小的块分配给每一个 Warp。
- Warp 将数据从 Shared Memory (28 cycles) 继续向上搬运到寄存器文件 Register File (0 cycles) 中。
- 第 3 层划分:Thread Tile (线程级片)
- 难点:GPU 线程之间是处于物理隔离的,无法互相读取对方寄存器里的数据。
- 应对:每个单独的线程必须尽可能把分配给自己的行列数据留在寄存器内,在内部完成大量的外积 (\(C = A \times B + C\)) 累加操作。
5. 优化方法:软件流水线 (Software Pipelining) 隐藏延迟
- 瓶颈:因为极致优化极大地消耗了寄存器,导致 GPU 内部能同时驻留并发运行的 Warp 变少,无法单纯靠“切线程”来完全掩盖那 350 cycles 的主存延迟。
- 优化:采用软件流水线。在当前周期执行数学计算指令 (Math/ALU) 的同时,立刻向内存系统发出下一次循环所需要的内存加载指令 (Load global/shared)。让读取和计算在时间轴上完美重叠(打破 Loop-carried dependency),达成 90% 以上的理论算力极限。
6.小结
- GPU体系结构
- GPU内存层次模型
- GPU执行模型
- 如何在GPU中实现高效矩阵乘法
PART 5:为深度学习定制的芯片:ASIC 与 TPU
1. 为什么 CPU 和 GPU 依然不够好?

2. TPU (Tensor Processing Unit)
- 降维(低精度量化):直接摒弃浮点,采用 8-bit 整型 (INT8) 作为底层计算数据类型。将庞大的浮点区间映射到
[min, max]的 256 个整数级别。这样省下的庞大物理面积,全换成了计算单元。 - 硬件规模:在仅 40W 功耗、28nm 工艺、700MHz 低频下,塞入了 65,536 个 8-bit 乘加单元 (GPU一般只有几千个 32-bit 单元)。
- CISC 级精简专精指令集:指令设计极其粗暴直接。如
MatrixMultiply(一键执行几万次乘加),Read_Weights,Activate。 - 海量片上缓冲:取消了复杂的 L1/L2 Cache 层级,直接在片上放一块巨大的 24MB SRAM (Unified Buffer),专门存激活值。
3.节省访存的核心:脉动阵列 (Systolic Array)
这是彻底解决“访存墙”的终极硬件设计思想。
- CPU/GPU 的问题:每一个 ALU 算完一个加法/乘法,都要走一遍硬件逻辑写回寄存器,下一个指令再读出来。读写寄存器的功耗和时间极其高昂。
- 脉动阵列设计思想(Data Flowing):
- 将 65536 个 ALU 像棋盘网格一样在物理层面上硬连线串联起来。
- 核心准则:在阵列内部流动计算,彻底避免中间过程的寄存器读写!
- 步骤拆解(矩阵 \(W \times\) 向量 \(x\)):
- 预载:将权重矩阵 \(W\) (\(w_{11}, w_{12}, w_{13} ...\)) 提前注入并锚定在阵列内部的各个 ALU 节点上。
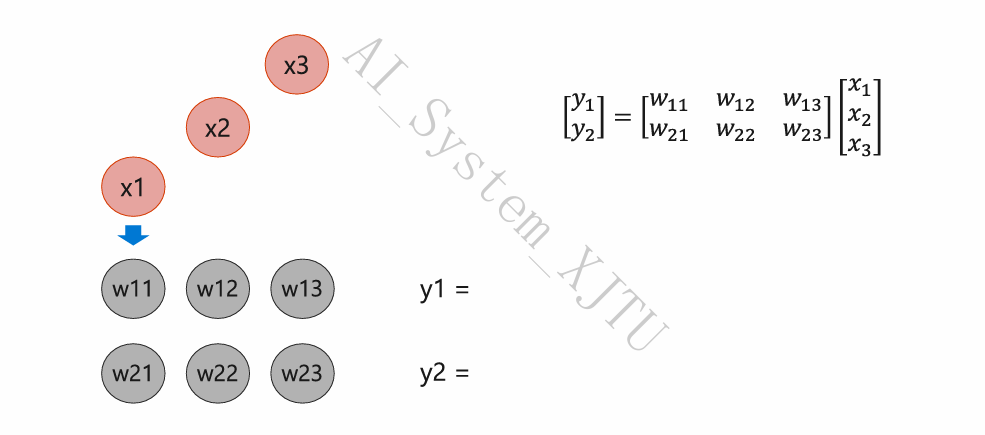
- 脉动泵入:输入向量数据 \(x_1, x_2, x_3\) 按固定的时钟节拍,从阵列的一端(左侧/上方)“泵”进去。
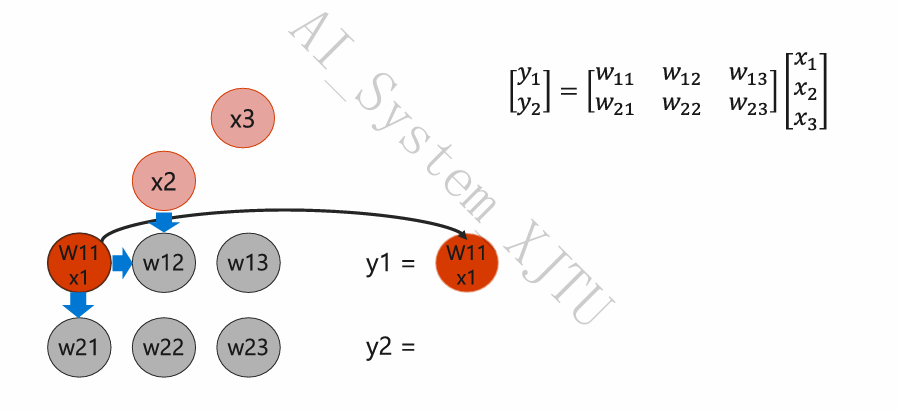
- 流水线接力:数据到达第一个 ALU 节点,执行 \(x_1 \times w_{11}\) 并加上来自上方节点的偏置。当前 ALU 算完后,不写回寄存器,而是通过物理导线直接将结果推给相邻的下一个 ALU。
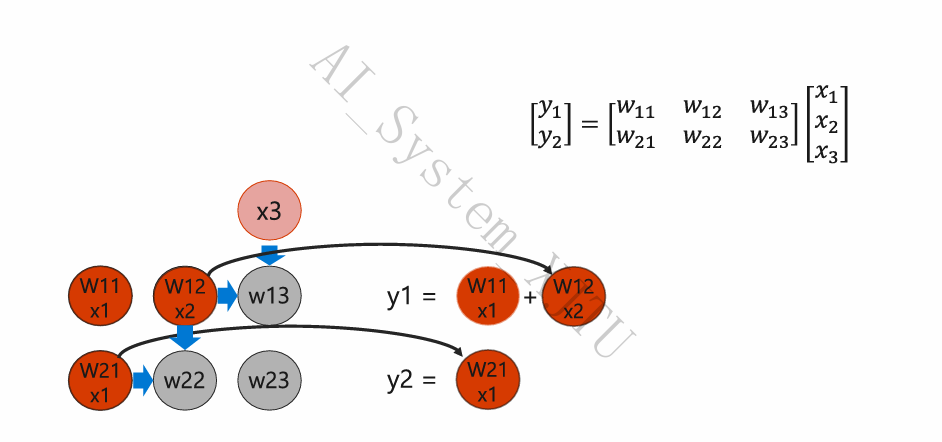
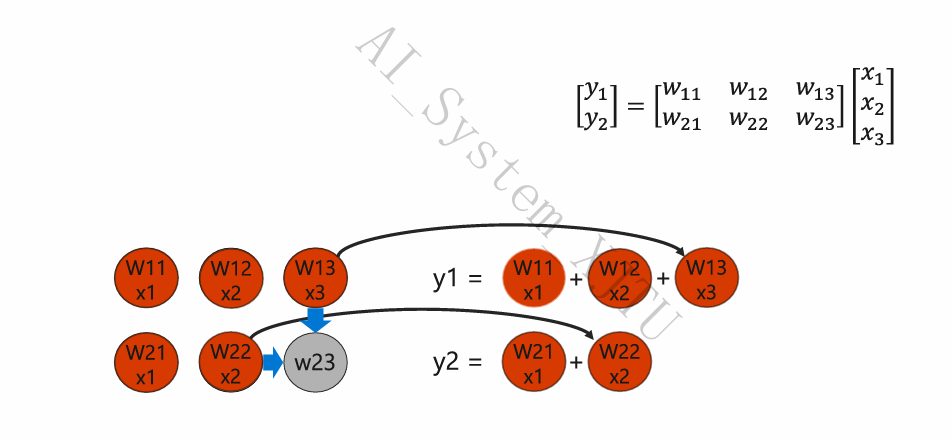
- 流出:随着时钟周期推进,各个分量的部分和在阵列中传递,最终完整的矩阵结果 \(y_1, y_2\) 从阵列另一侧的边缘流出。
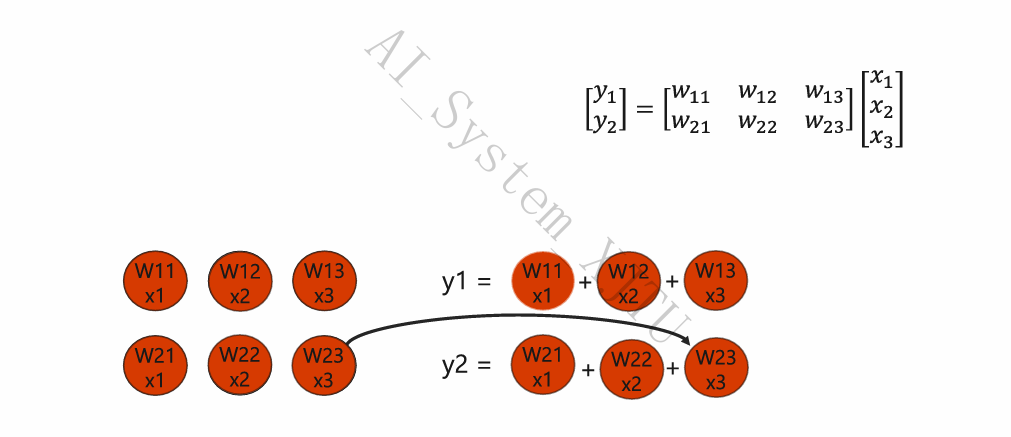
- 预载:将权重矩阵 \(W\) (\(w_{11}, w_{12}, w_{13} ...\)) 提前注入并锚定在阵列内部的各个 ALU 节点上。
- 总结:ASIC (TPU) 通过牺牲所有的通用灵活性,换取了在特定任务(矩阵乘法)上数十倍于 GPU 的能效比和计算密度。